

Part 1: Exabyte Scale Object Storage Systems
Part 1: Exabyte Scale Object Storage Systems
How Facebook and Microsoft Are Doing

Storing files or object binaries at Exabyte scale and beyond presents challenges due to current hardware limitations. Addressing these challenges requires leveraging solid theoretical foundations and adhering to scalable design principles. With the advent of generative AI, the rate of content creation has surged, compelling us to consider designing zettabyte-scale storage solutions in the near future.
This write-up is based on two key papers:
"f4: Facebook’s Warm BLOB Storage System" – This paper details the design of Facebook's "f4" system for handling their blob storage.
"Erasure Coding in Windows Azure Storage" – This paper from Microsoft outlines the design of their "Windows Azure Storage" system.
We will soon dive into various design approaches, but it is crucial first to understand the design goals of companies undertaking large-scale storage system projects.
The goal of this post is twofold:
Identify Hardware Building Blocks: Highly scalable systems have clearly defined and designed building blocks that enable them to scale services at different tiers and layers simply by adding them horizontally. Hardware decisions are never made in isolation; they must be considered alongside the design decisions of the software running on them. Both need to be explored within the broader system context.
Provide Design Insights: Offer insights and design inspirations for those considering designing a system of this nature.
In follow-up posts in this series, we will methodically explore topics such as erasure coding and other related subjects, focusing on designing an object storage system that operates on this hardware infrastructure.
Design Goals
Under all reasonably conceivable software and hardware failure scenarios, a system of this nature is expected to provide:
Fault Tolerance for High Durability: Ensuring data is not lost despite failures.
Fault Tolerance for High Availability: Ensuring continuous access to data even during failures.
Efficiency in Storage Capacity: Maximizing storage capacity to improve cost-effectiveness ($/GB/MW).
Efficiency in Supporting Distinct Usage Patterns: Accommodating both frequent and infrequent write and access patterns.
To understand how software can scale with hardware and how it can fail due to hardware issues, we must first derive an optimal hardware topology for a datacenter and interconnected datacenters across large geographic distances.
Hardware Infrastructure Topology
At the Exabyte scale, it makes sense for a company to own its hardware. At this scale, relying on third-party vendors can substantially impact your profit margins due to their increased profit margins. However, this decision carries risks and should be made within the context of the specific business.
Taking control of your hardware does not necessarily mean building your own datacenter; this can still be outsourced to colocation facilities. These facilities typically operate in two modes:
Renting Colocation Space with Remote Access:
You rent space in a datacenter (DC) with options for micro-zoning and zonal physical security measures.
You do not have direct access to the premises. Instead, you have remote access to a DC operations team for provisioning, deprovisioning, and maintenance.
Options vary between DC vendors.
Renting Colocation Space with On-Site Access:
You rent a colocation space where you have a private suite and can station your own DC operations teams.
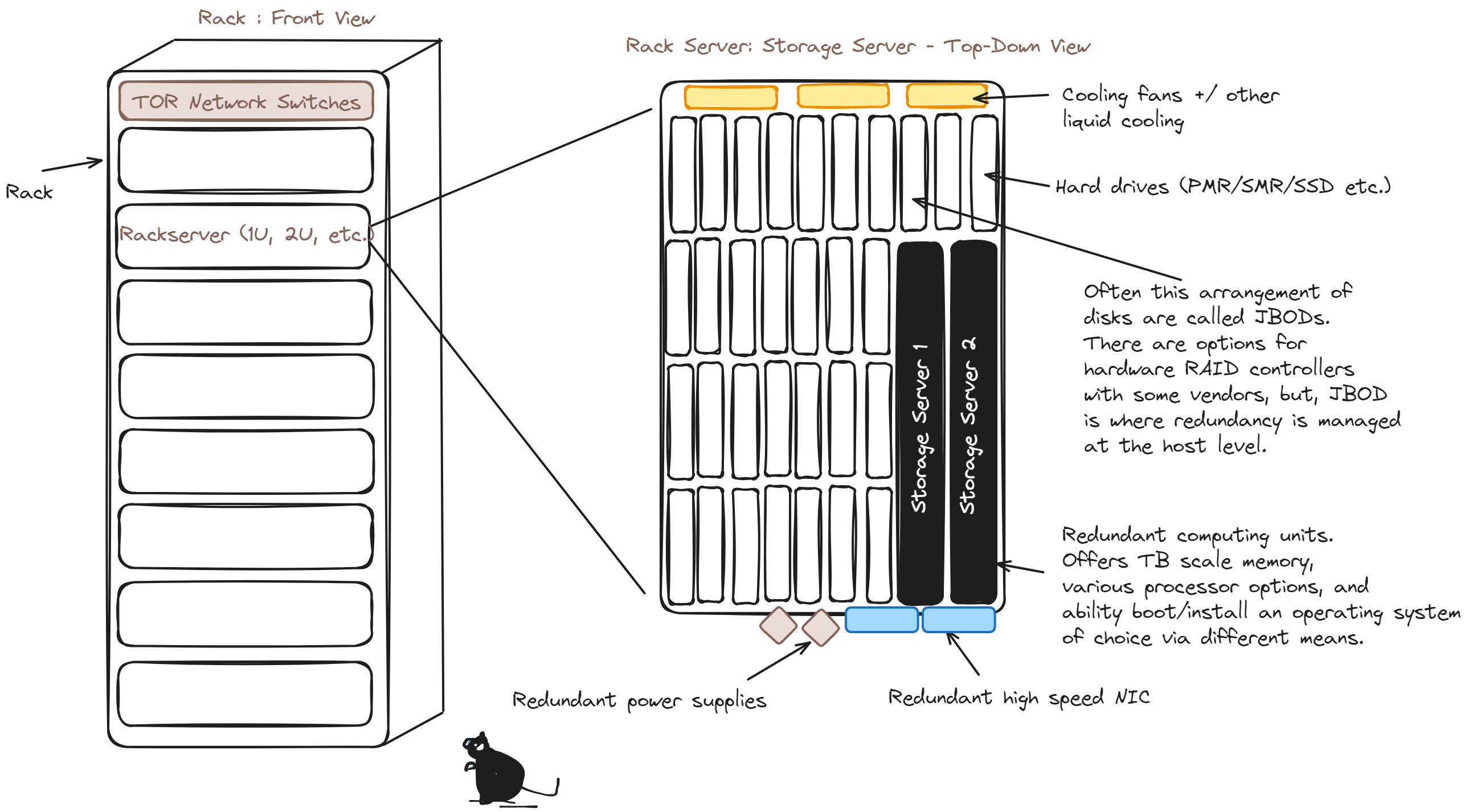
Datacenters are typically filled with arrays of racks, which are the de facto units of scale at the DC level. Within these racks are individual blade servers or rack servers, measured in rack units (U), such as 1U or 2U.
When hosting your hardware in a colocation setup, you usually rent out space for entire racks rather than individual rack servers. Typically, you do not share a single rack with other customers, especially at the Exabyte scale.
Increasing storage capacity often involves provisioning additional rack servers, which requires additional hardware for networking, power supply, and other necessities. We will discuss these further.
Regional DC Model
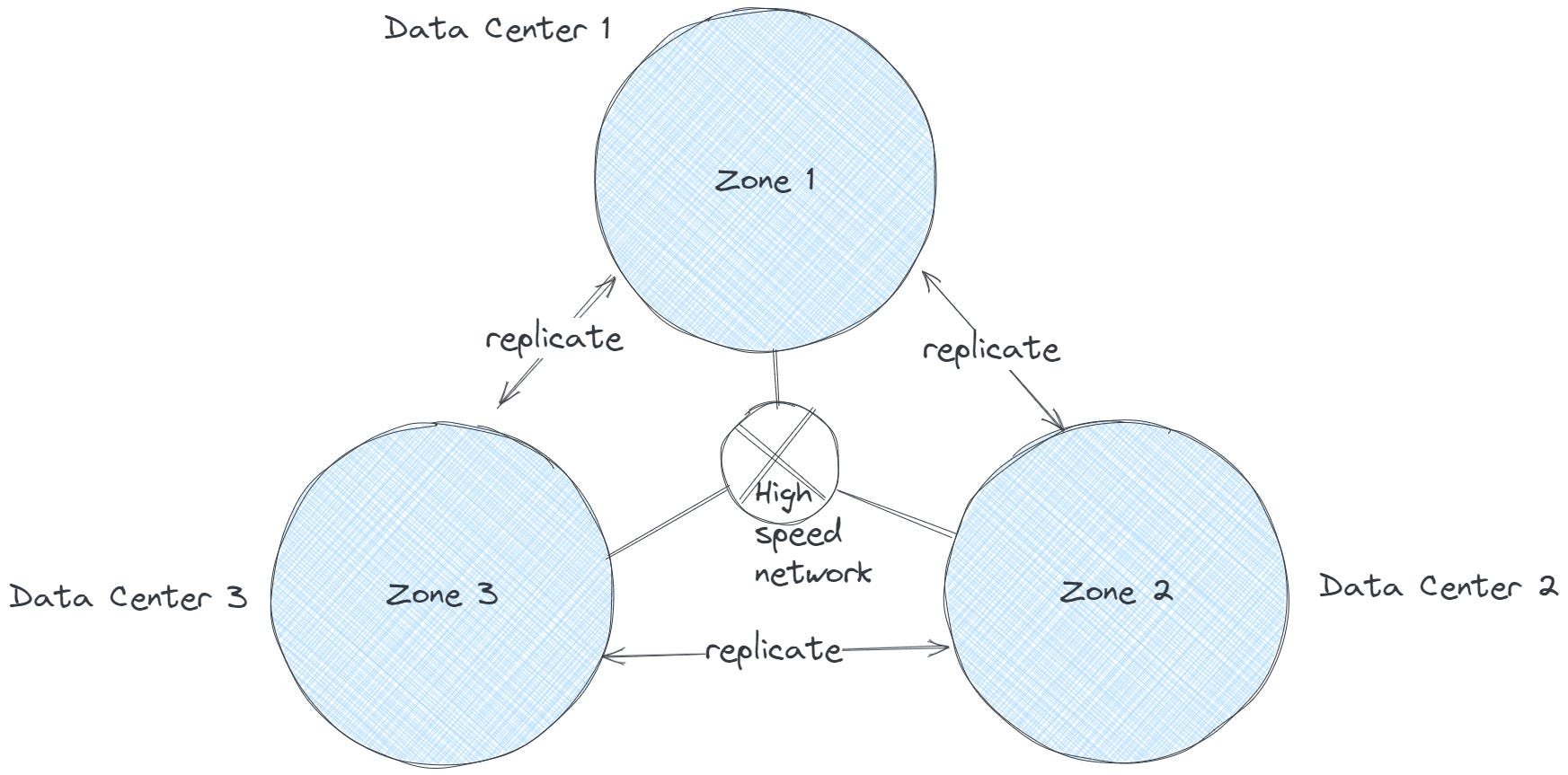
When renting datacenter (DC) space, companies often adopt a regional model, distributing colocation spaces across different geographic regions. These regions may lie within a single jurisdiction or across multiple jurisdictions, strategically located closer to users. While we will discuss this in more detail later, for now, consider that these regional centers are connected via a high-speed, high-throughput edge network.
Design Considerations
When designing an binary object storage system, it's essential to consider both the software and hardware components, which are typically layered. At this stage, the focus is on keeping the design abstract enough to understand the fundamentals while addressing the following key aspects:
Write Efficiency to Physical Storage Media:
How can we optimize the process of writing data to storage media?
Read Efficiency from Physical Storage Media:
How can we ensure fast and reliable data retrieval from storage media?
Data Storage Efficiency:
How efficiently can we store data?
What is the yield we can expect, and how can we improve it?
Optimal Unit of Data for Replication:
What is the appropriate unit of data (e.g., 1MB, 1GB) for replication (let's call it a binary object)?
Data Distribution for High Availability and Durability:
How can we efficiently distribute data across the required number of failure domains to meet high availability (HA) and durability service-level agreements (SLAs)?
Hardware Management:
How do we detect new hardware additions, disk failures, and draining requests, and how should the system react to these events?
File System Considerations:
Should we use a filesystem on the rack server (which we'll refer to as binary storage devices) or write directly to the disks?
Key Software Components:
What are the critical software components that need to run on the hardware?
What roles do these components play within the larger system context?
Assumptions
While there are emerging storage technologies like Heat-Assisted Magnetic Recording (HAMR) and Microwave-Assisted Magnetic Recording (MAMR), for the purpose of this discussion, we will assume our hardware leverages Shingled Magnetic Recording Hard Disk Drives (SMR-HDDs). These drives offer the best cost per GB storage but come with limitations on random writes. Dropbox is known to extensively use this technology in their MagicPocket implementation.
The nature of this service involves providing object history, meaning objects are not modified once written. This makes SMR-HDDs an ideal choice for such a condition.
The Ubiquitous Language
Before delving further into this topic, let's ensure we're using common terminology. This aligns with one of the key principles of Domain-Driven Design. Let's consider the following diagram as a reference for our discussion:
Region
This refers to the geographic region housing a Datacenter (DC). Typically, regions are chosen to be strategically distant (within a single jurisdiction or across borders) to minimize the impact of natural disasters and geopolitical uncertainties. Additionally, proximity to current user bases and potential future market expansions are key considerations in the selection process.
Datacenter (DC)
Referring to a datacenter (DC) within a region implies the possibility of multiple datacenters coexisting in that area. When seeking to expand capacity within a single region, options include augmenting hardware capacity at an existing datacenter or establishing a new one altogether.
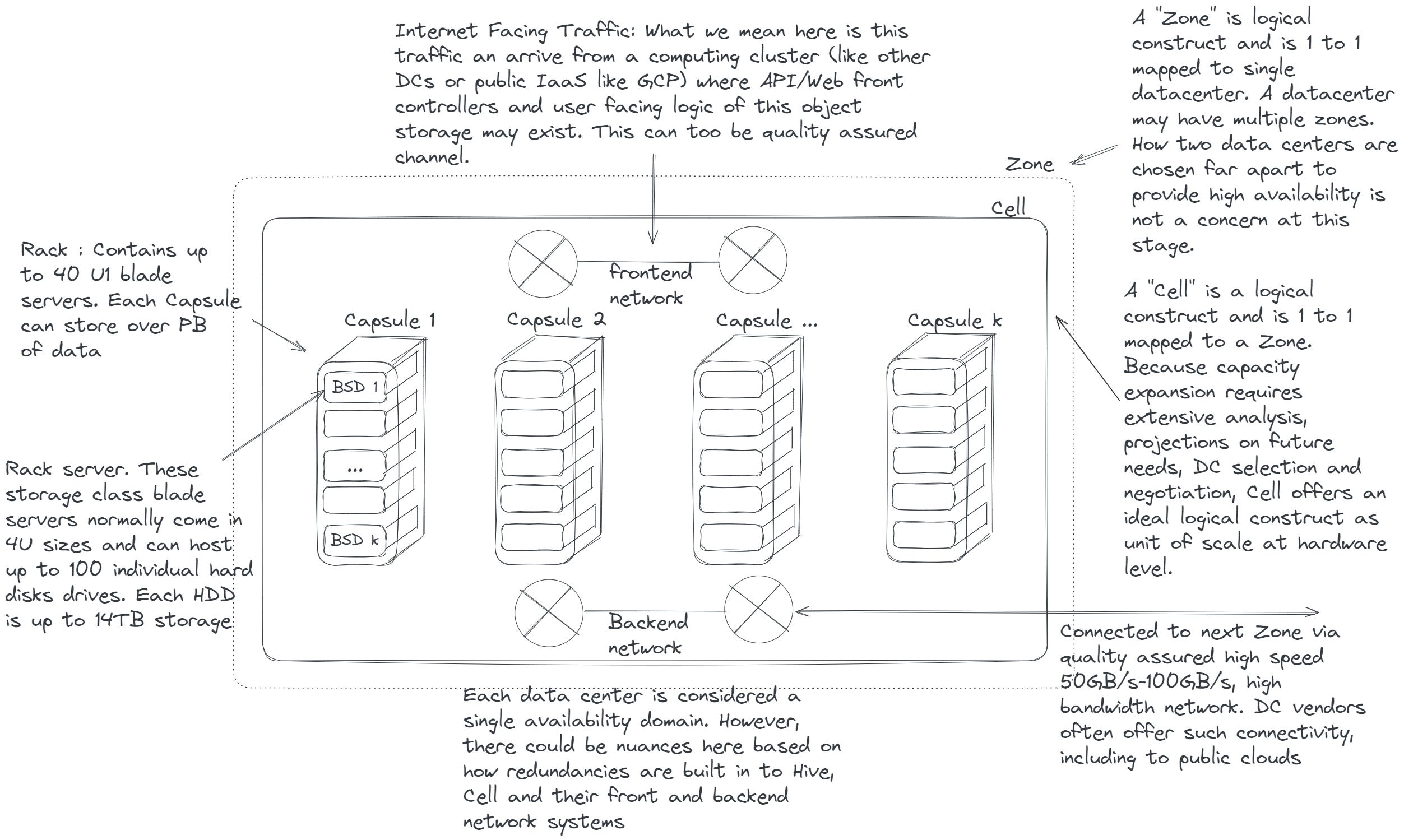
Zone
A zone is a logical construct uniquely mapped to a single datacenter. This abstraction enables the separation of the physical datacenter from its software components. Each zone serves as a high availability domain for software and its deployment. While multiple zones can exist within a single datacenter, maintaining a one-to-one mapping of zones to datacenters is advisable, particularly in regions with multiple datacenter availability.
Cell
A cell functions as a logical unit of capacity within a zone, and a zone may encompass multiple cells. Planning for capacity expansion at the data center level demands meticulous groundwork, involving analysis and forecasting of future capacity requirements, negotiation of power budgets with the data center, spatial arrangements and isolation, network design, bandwidth negotiations, and various other considerations. Therefore, when provisioning new capacity, especially for an exabyte-scale storage system, a "Cell" serves as a logical unit of scale, providing essential decoupling from physical constructs. A Cell can represent one or more physical racks, network switches, cooling systems, and other vital infrastructure components. Upon integrating a cell into existing capacity, the software layer may require discovery, identification, and communication with the cell across the network. Additionally, the concept of a cell can efficiently accommodate any Quality of Service (QoS) requirements for a system of this magnitude, such as delineating hot, warm, and cold storage needs.
An essential strategy I intend to adopt is maintaining uniform hardware across all cells, ensuring homogeneity to facilitate seamless operations.
Capsule
A capsule denotes a physical rack containing multiple rack servers. In contemporary datacenter designs, racks typically incorporate redundancy measures for network, power, cooling, fire control, and other vital functions, thus establishing a localized availability domain. Consequently, within a cell, where data is stored, the software must possess the capability to discover, identify, communicate with, and harness such localized failure domains to enhance availability.
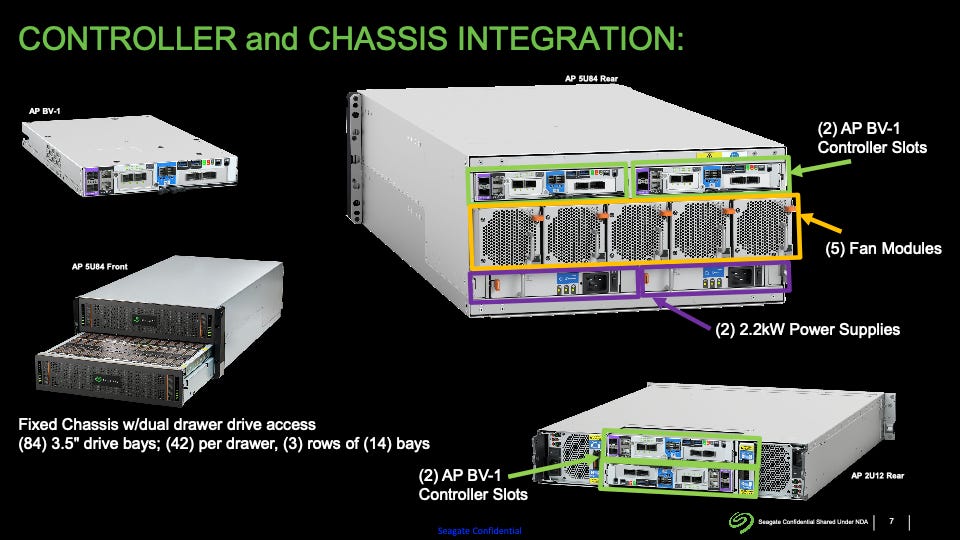
BLOB Storage Device (BSD)
At this stage of system design, we focus on Binary Large Objects (BLOBs), a term borrowed from the relational database realm. The devices that store them are known as BLOB Storage Devices (BSDs). These BSDs are the physical storage devices responsible for storing data across multiple hard disks or other storage media such as Solid State Drives (SSDs). These hardware components are also referred to as rack servers. Please refer to Figure 1.0 for visualization. The methods by which data is distributed across individual disks to ensure recoverability in the event of hardware failures, as well as strategies for optimizing retrieval and write speeds, will be explored in detail in part 2 of this series.
Application Controller
The Application Controller (APC) serves as an autonomous processing unit within the BLOB Storage Device (BSD). It oversees a set of HDDs or SSDs, powered by multi-core processors, often in a dual processor configuration. By integrating the APC with the disks they manage, a remarkably compact hardware profile is achieved.
Storage Node
Storage Nodes (or simply Nodes) are a logical construct. Each Storage Node is associated with a single Application Controller, with one storage node service daemon running per Application Controller. In the second part of this series, we will delve deeper into their functionalities and roles.
Let’s Talk Bit More About BSD
Multiple vendors, including Seagate, Samsung, IBM, Dell, and HP, offer BLOB Storage Devices (BSDs) with various hardware options. As mentioned earlier, we will opt for Shingled Magnetic Recording (SMR) BSDs to maximize our GB/$ yield, a significant cost-saving measure. While this may not be the primary consideration for a company managing terrabytes of data over the next decade, it presents substantial savings for a system of this scale, as demonstrated by Dropbox's adoption of this technology. In part 2, we will delve into how SMR hardware aligns with the immutable nature of the data we intend to store and the associated constraints. For now, let's explore a real-life reference.


Let’s demystify this hardware a bit more as it is a crucial component in our hardware topology. Here is a datasheet of the above hardware for your reference.
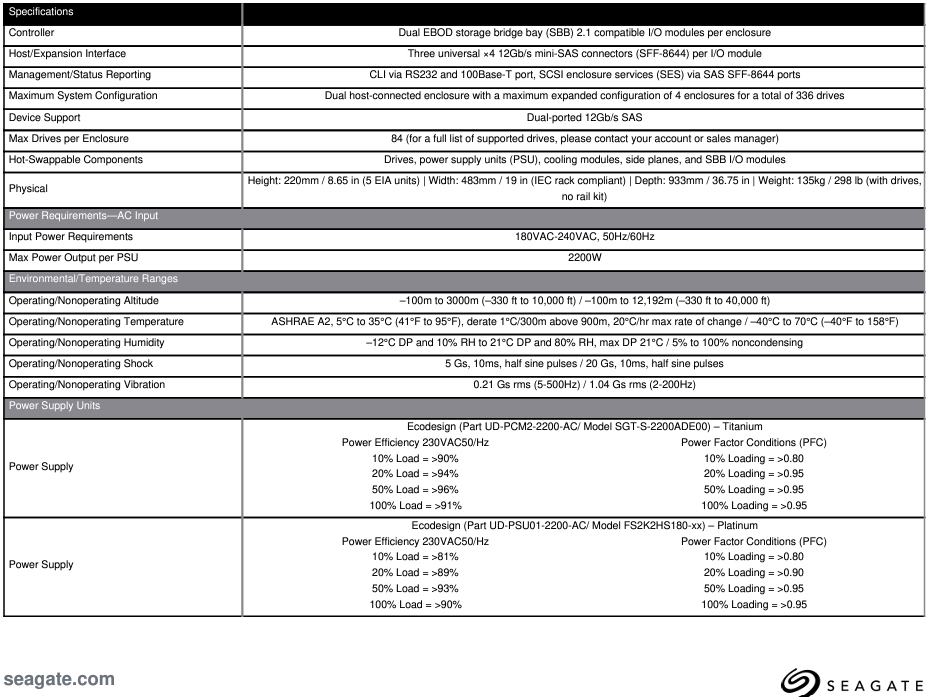
These hardware devices commonly incorporate redundant "computing units," also known as Application Controllers (APCs), designed to execute the server software. These computing units typically utilize standard processors, serving as the central processing unit for device management and network communication. Additionally, these devices often feature firmware and drivers tailored to manage the numerous disks installed within the device and utilities to monitor hardware health. Below is a detailed specification of an APC for further reference.
Minimum Configuration
With a quorum of three of these BLOB Storage Devices (BSDs), we can establish the minimum infrastructure necessary to deliver our service. From this foundation, we can systematically expand the capacity to form the first complete Cell. With a minimum of three nodes, our hardware topology would resemble the following:
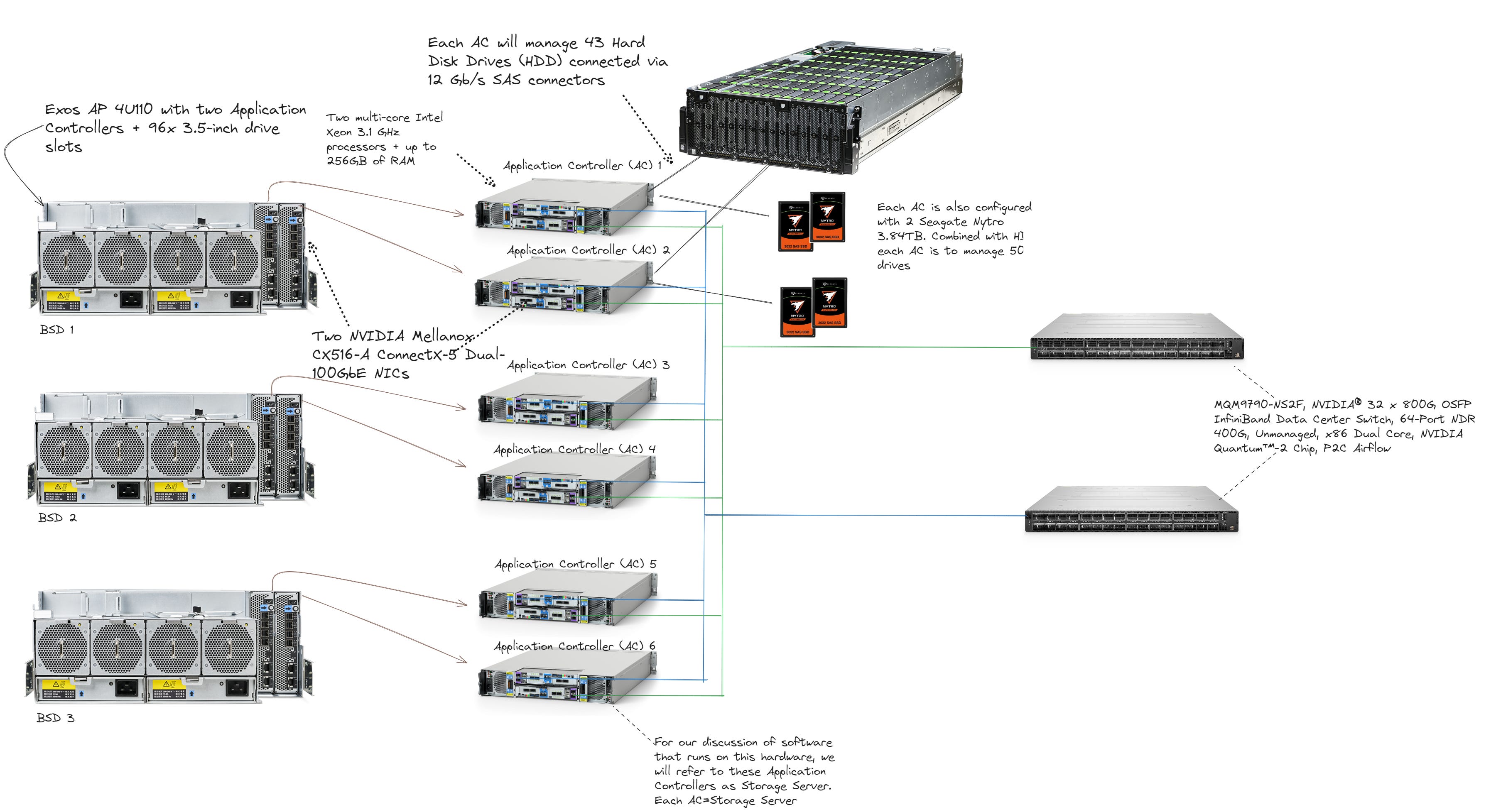
In the above configuration APC is configured in shared-nothing mode, effectively making them independent storage nodes.
In this setup, we can deploy a daemon software service to manage the coordination of reading and writing to HDDs. While each of these Application Controllers (APCs) will run an operating system, the necessity of a file system for reading and writing to individual disks, as well as the methods employed for data striping, erasure coding, and distribution across multiple HDDs to ensure availability, are all determined by this daemon and other auxiliary services that can operate on this hardware node. For instance, open-source solutions like the Ceph daemon provide similar functionalities, although we are primarily focused on handling read and write operations to disks without the additional overhead of filesystems.
In upcoming posts, we will delve into the development of our own daemon, tailored specifically to efficiently manage disk operations. The SSDs integrated into these APCs serve as a means to cache certain write and read operations, mitigating the limitations of mechanical storage mediums. Additionally, it's crucial to consider that all storage mediums, including Nonvolatile Solid State Drives (SSDs), have a maximum number of write operations they can support before their performance begins to degrade due to increased error rates.
One might consider running containers on APCs to execute these daemons. However, such decisions should be carefully benchmarked to ensure that any additional overhead does not consume the limited hardware resources on each APC. In part 2 of this write-up, we will delve deeper into these software components and their operations.
In part 2, we will dive into the even more exciting software aspects of this design. Stage tuned.